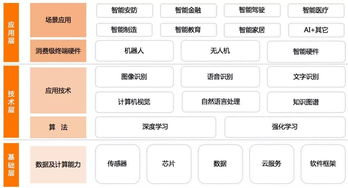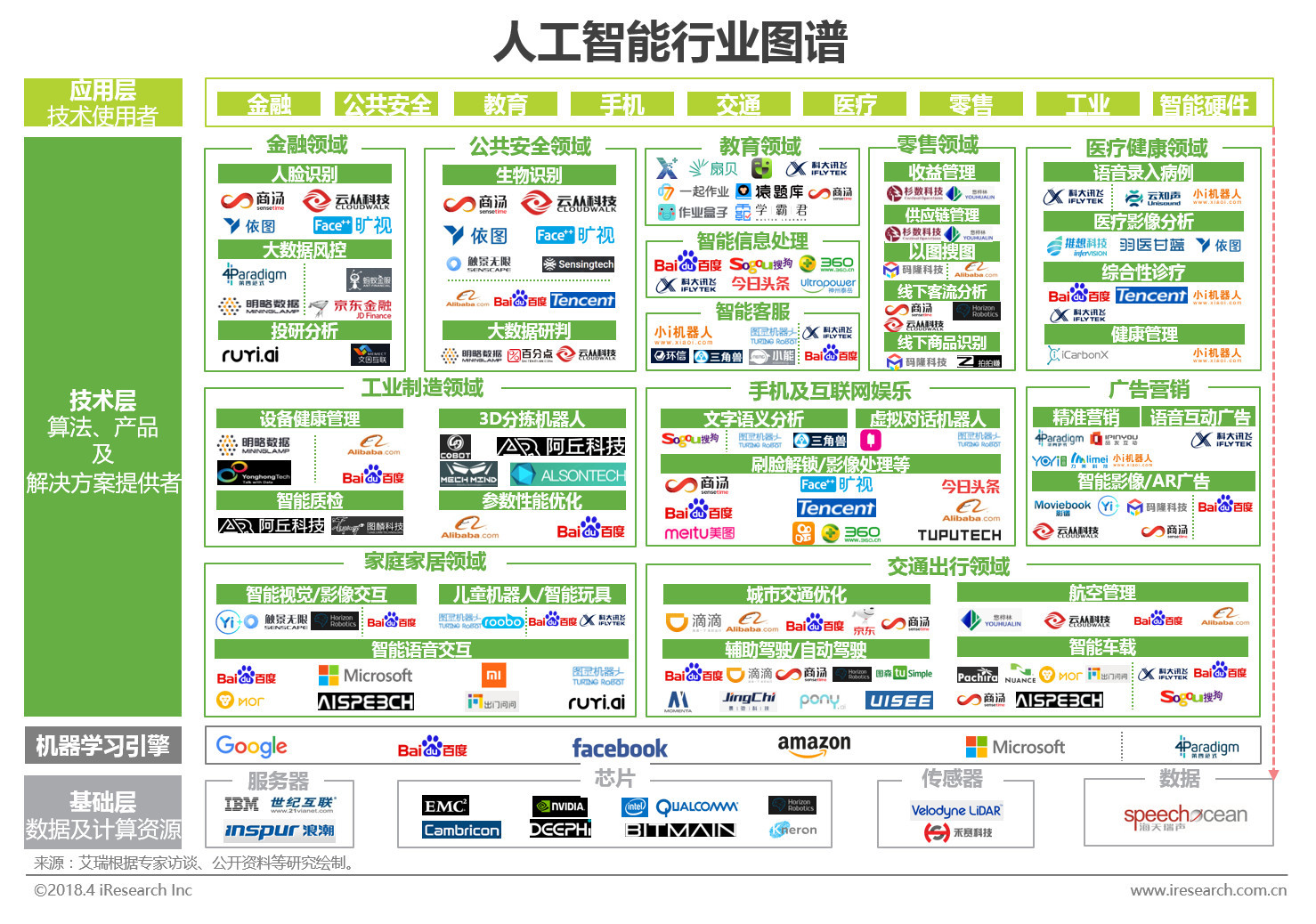
2018年,中國人工智能行業在基礎資源與技術領域取得了顯著進展,為產業應用的爆發奠定了堅實基礎。本報告將深入剖析該年度中國AI在算力、數據、算法及關鍵使能技術方面的核心動態與發展趨勢。
一、 算力基礎:芯片競逐與云端協同
算力是人工智能發展的引擎。2018年,中國在AI計算芯片領域呈現多元化發展格局。一方面,以英偉達GPU為代表的通用芯片在數據中心訓練場景中仍占據主導,國內云服務商(如阿里云、騰訊云、百度云)大規模部署,提供了強大的云端AI算力服務。另一方面,中國AI芯片設計公司迎來發展熱潮,寒武紀、地平線、比特大陸等企業分別在云端、終端及專用領域推出AI芯片,尋求在特定場景下的性能與能效突破。國家層面推動的先進計算基礎設施(如超算中心)也開始更緊密地與AI計算融合,形成“超算+智算”的混合算力模式。
二、 數據資源:規模擴張與治理挑戰
數據是訓練AI模型的燃料。2018年,中國憑借龐大的網民基數和豐富的應用場景,在數據資源規模上持續領先。互聯網巨頭、電信運營商及垂直行業企業積累了海量的文本、圖像、語音及用戶行為數據。數據的價值釋放面臨兩大關鍵挑戰:一是數據孤島問題突出,跨企業、跨行業的數據流通與協作機制尚不健全;二是數據安全與隱私保護法規日趨嚴格(如《網絡安全法》的實施),如何在合規前提下高效利用數據成為行業共同課題。推動數據標注標準化、發展隱私計算技術(如聯邦學習)成為當年的重要探索方向。
三、 算法突破:開源生態與創新應用
算法是AI系統的靈魂。2018年,中國AI算法研究在學術層面緊跟全球前沿,在計算機視覺、自然語言處理等領域論文發表量位居世界前列。更重要的是,產業實踐推動了算法的快速落地與迭代。國內科技公司積極擁抱并貢獻于TensorFlow、PyTorch等國際主流開源框架,同時也在推動自主開源生態(如百度的PaddlePaddle)。在應用算法層面,基于深度學習的目標檢測、語義分割、機器翻譯、語音合成等技術成熟度顯著提升,開始大規模集成到安防、金融、醫療、內容創作等具體產品中。遷移學習、小樣本學習等旨在降低數據依賴的新興算法受到更多關注。
四、 關鍵使能技術:感知與認知的深化
在具體技術維度,2018年的發展呈現出從“感知智能”向“認知智能”延伸的態勢。
- 計算機視覺:技術已高度商業化,在安防監控、手機解鎖、金融身份認證等領域普及,同時向工業質檢、自動駕駛等對可靠性與精度要求更高的領域滲透。動態識別、3D視覺成為熱點。
- 自然語言處理:在智能客服、搜索引擎優化等應用驅動下持續進步,預訓練語言模型(如BERT,同年發布)開始展現潛力,為后續的突破埋下伏筆。語義理解的深度仍是攻堅重點。
- 語音技術:智能音箱市場的爆發帶動了遠場語音識別、語音喚醒、方言識別等技術的快速成熟,語音交互成為重要的人機接口。
- 知識圖譜:作為連接感知與認知的關鍵技術,在金融風控、智能推薦、醫療輔助診斷等領域構建行業知識模型的需求旺盛,大規模自動化構建技術得到發展。
五、 與展望
2018年是中國人工智能基礎資源與技術承前啟后的關鍵一年。算力層面呈現“云端強、終端追”的格局;數據在規模優勢下尋求合規高效的利用之道;算法依托開源生態快速產業化;各項使能技術則在廣泛的應用場景中錘煉升級。核心芯片對國外依賴度較高、尖端原創算法有待突破、高質量數據生態不完善等短板依然存在。夯實基礎層的技術自主性與協同效率,將是支撐中國人工智能產業行穩致遠、從“應用大國”邁向“技術強國”的根本保障。